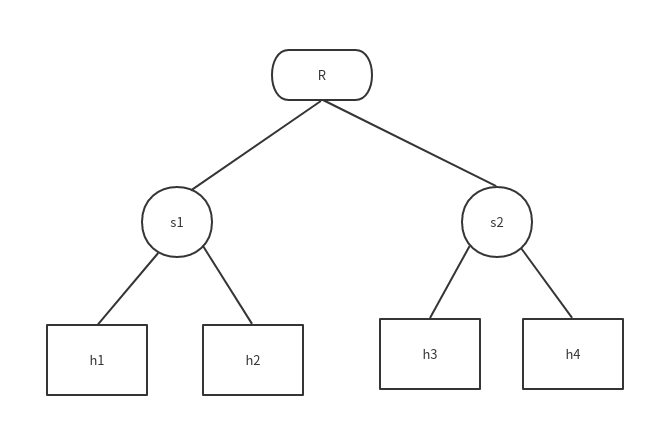
root@mininet-vm:/home/mininet# ip netns exec n2 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
可以执行ip netns exec n2 bash,之后所有指令都在指定namespace中执行而不需要加上ip netns exec name
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
root@mininet-vm:/home/mininet# ip netns exec n2 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 root@mininet-vm:/home/mininet# ip netns exec n2 bash root@mininet-vm:/home/mininet# ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 root@mininet-vm:/home/mininet# exit exit root@mininet-vm:/home/mininet# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast .................
使用命令ip link add type veth创建一对veth pair,其默认名是veth0和veth1,使用ip link可查看链接
1 2 3 4 5 6 7 8 9 10 11
root@mininet-vm:/home/mininet# ip link ..... 3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN root@mininet-vm:/home/mininet # ip link add type veth root@mininet-vm:/home/mininet # ip link .... 3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN 9: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 12:e8:a5:43:c0:43 brd ff:ff:ff:ff:ff:ff 10: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 9e:f8:c3:b9:af:ec brd ff:ff:ff:ff:ff:ff
2. 将veth pair的两端分别放到两个namespace
使用命令ip link set veth0 netns n1和ip link set veth1 netns n2分别将veth0和veth1放到不同namespace
1 2 3 4 5 6 7 8 9 10 11 12
oot@mininet-vm:/home/mininet# ip link set veth0 netns n1 root@mininet-vm:/home/mininet# ip link set veth1 netns n2 root@mininet-vm:/home/mininet# ip netns exec n1 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 9: veth0@if10: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 12:e8:a5:43:c0:43 brd ff:ff:ff:ff:ff:ff root@mininet-vm:/home/mininet# ip netns exec n2 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 10: veth1@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 9e:f8:c3:b9:af:ec brd ff:ff:ff:ff:ff:ff
3. 为veth pair的两端分别配置ip
使用命令ip link set vethX up和ip addr add 10.0.0.10/24 dev vethX为veth pair配置ip,结果如下
# namespace 1 namespace ns1> ip link set veth0 up namespace ns1> ip a 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 9: veth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 12:e8:a5:43:c0:43 brd ff:ff:ff:ff:ff:ff namespace ns1> ip addr add 10.0.10.1/24 dev veth0 namespace ns1> ip a 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 9: veth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 12:e8:a5:43:c0:43 brd ff:ff:ff:ff:ff:ff inet 10.0.10.x1/24 scope global veth0 valid_lft forever preferred_lft forever
# namespace 2 namespace n2>ip link set veth1 up namespace n2>ip addr add 10.0.10/24 dev veth1 namespace n2>ip a 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 10: veth1@if9: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state LOWERLAYERDOWN group default qlen 1000 link/ether 9e:f8:c3:b9:af:ec brd ff:ff:ff:ff:ff:ff inet 10.0.10.0/24 scope global veth1 valid_lft forever preferred_lft forever
4. 测试两个namespace之间的网络联通状态
分别在n1和n2中尝试ping
1 2 3 4 5 6
namespace ns1> ping 10.0.10.0 -c 1 PING 10.0.10.0 (10.0.10.0) 56(84) bytes of data. 64 bytes from 10.0.10.0: icmp_seq=1 ttl=64 time=0.035 ms namespace n2>ping 10.0.10.1 -c 1 PING 10.0.10.1 (10.0.10.1) 56(84) bytes of data. 64 bytes from 10.0.10.1: icmp_seq=1 ttl=64 time=0.040 ms
root@mininet-vm:/home/mininet# ip netns add n3 root@mininet-vm:/home/mininet# ip netns add n4 root@mininet-vm:/home/mininet# ip netns ls n4 n3 n1 n2
2. 创建bridge
1 2 3 4 5 6 7 8 9 10 11 12 13 14
root@mininet-vm:/home/mininet# ip link add br0 type bridge root@mininet-vm:/home/mininet# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:1e:27:79 brd ff:ff:ff:ff:ff:ff inet 192.168.117.128/24 brd 192.168.117.255 scope global eth0 valid_lft forever preferred_lft forever 3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default link/ether 72:f5:e5:5d:4d:ed brd ff:ff:ff:ff:ff:ff 11: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default link/ether 76:d8:06:1a:b9:84 brd ff:ff:ff:ff:ff:ff
3. 利用veth pair将bridge与n3、n4、n1连通
创建3对veth pair
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
root@mininet-vm:/home/mininet# ip link add type veth root@mininet-vm:/home/mininet# ip link add type veth root@mininet-vm:/home/mininet# ip link add type veth root@mininet-vm:/home/mininet# ip a ... 11: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default link/ether 76:d8:06:1a:b9:84 brd ff:ff:ff:ff:ff:ff 12: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether ea:98:b6:3c:46:60 brd ff:ff:ff:ff:ff:ff 13: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether f2:f6:d8:6b:31:1f brd ff:ff:ff:ff:ff:ff 14: veth2@veth3: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 4a:7d:af:18:67:14 brd ff:ff:ff:ff:ff:ff 15: veth3@veth2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether ca:b6:e4:eb:b7:15 brd ff:ff:ff:ff:ff:ff 16: veth4@veth5: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether f2:b3:5f:0e:3d:09 brd ff:ff:ff:ff:ff:ff 17: veth5@veth4: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 76:0c:87:b1:16:80 brd ff:ff:ff:ff:ff:ff
# 启动网桥(网桥只需要启动一次就行) ip link set br0 up # 创建vethpair ip link add br-1 type veth peer name 1-br #将vethpair分配给网桥和namespace ip link set br-1 master br0 ip link set 1-br netns n1 #启动veth ip link set br-1 up ip netns exec n1 ip link set 1-br up # 为namespace中的veth设置ip ip netns exec n1 ip addr add 10.0.10.2/24 dev 1-br
mininet> sh ovs-vsctl add-port s13vxlan ovs-vsctl: Error detected while setting up 'vxlan': could not open network device vxlan (No such device). See ovs-vswitchd log for details. ovs-vsctl: The default log directory is "/var/log/openvswitch".
解决方案如下
1 2
The port‘s name should be a exist interface use ifconfig to see, such as eth0. If you just want to use a virtual port name to make a test you should specify the port's type like ovs-vsctl add-port br0 port0 -- set Interface port0 type=internal or ovs-vsctl set Interface port0 type=internal
将指令改为
1
sh ovs-vsctl add-port s3 vxlan -- set Interface vxlan type=internal
在虚拟机中输入以下指令
1
sh ovs-vsctl set interface vxlan type=vxlan option:remote_ip=10.0.0.7 option:key=100 ofport_request=10
意义:连续 n 到 m 个的 “ 前一个 RE 字符 ” 意义:若为 {n} 则是连续 n 个的前一个 RE 字符, 意义:若是 {n,} 则是连续 n 个以上的前一个 RE 字符! 范例:在 g 与 g 之间有 2 个到 3 个的 o 存在的字串,亦即 ( goog )( gooog ) grep -n 'go\{2,3\}g' regular_express.txt
第十二章 shell脚本
1 2 3 4 5 6 7 8 9
#!/bin/bash #program # creat one file named by user's input and date command
make([]T, len) make([]T, len, cap) // same as make([]T, cap)[:len]
内置的append函数用于向slice追加元素:
1 2 3 4 5
var runes []rune for _, r := range"Hello, 世界" { runes = append(runes, r) } fmt.Printf("%q\n", runes) // "['H' 'e' 'l' 'l' 'o' ',' ' ' '世' '界']"
结构体
结构体一般格式
1 2 3
type name struct{ ... }
一个结构体可能同时含有导出成员和未导出成员
点操作符也可以和指向结构体的指针一起工作:
1 2
var employeeOfTheMonth *Employee = &dilbert employeeOfTheMonth.Position += " (proactive team player)"
相当于下面语句
1
(*employeeOfTheMonth).Position += " (proactive team player)"
结构体比较
若结构的所有成员都是可比较的,则结构体是可比较的当结构体所有成员都相等时,结构体变量相等
嵌入和匿名
结构体可以嵌入到另一个结构体中
匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针
对于匿名嵌入,可以直接访问叶子属性而不需要给出完整的路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
type Point struct { X, Y int } type Circle struct { Point Radius int } type Wheel struct { Circle Spokes int } var w Wheel w.X = 8// equivalent to w.Circle.Point.X = 8 w.Y = 8// equivalent to w.Circle.Point.Y = 8 w.Radius = 5// equivalent to w.Circle.Radius = 5 w.Spokes = 20
函数
声明
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
1 2 3
funcname(parameter-list)(result-list){ body }
以下4中声明所代表的含义相同
1 2 3 4 5 6 7 8
funcadd(x int, y int)int {return x + y} funcsub(x, y int)(z int) { z = x - y; return} funcfirst(x int, _ int)int { return x } funczero(int, int)int { return0 } fmt.Printf("%T\n", add) // "func(int, int) int" fmt.Printf("%T\n", sub) // "func(int, int) int" fmt.Printf("%T\n", first) // "func(int, int) int" fmt.Printf("%T\n", zero) // "func(int, int) int"
// CountWordsAndImages does an HTTP GET request for the HTML // document url and returns the number of words and images in it. funcCountWordsAndImages(url string)(words, images int, err error) { resp, err := http.Get(url) if err != nil { return } doc, err := html.Parse(resp.Body) resp.Body.Close() if err != nil { err = fmt.Errorf("parsing HTML: %s", err) return } words, images = countWordsAndImages(doc) return } funccountWordsAndImages(n *html.Node)(words, images int) { /* ... */ }
// squares返回一个匿名函数。 // 该匿名函数每次被调用时都会返回下一个数的平方。 funcsquares()func()int { var x int returnfunc()int { x++ return x * x } } funcmain() { f := squares() fmt.Println(f()) // "1" fmt.Println(f()) // "4" fmt.Println(f()) // "9" fmt.Println(f()) // "16" }
函数squares返回另一个类型为 func() int 的函数。对squares的一次调用会生成一个局部变量x并返回一个匿名函数。每次调用时匿名函数时,该函数都会先使x的值加1,再返回x的平方。第二次调用squares时,会生成第二个x变量,并返回一个新的匿名函数。新匿名函数操作的是第二个x变量。
注意捕获迭代变量
1 2 3 4 5 6 7 8 9 10 11 12
var rmdirs []func() for _, d := range tempDirs() { dir := d // NOTE: necessary! os.MkdirAll(dir, 0755) // creates parent directories too rmdirs = append(rmdirs, func() { os.RemoveAll(dir) }) } // ...do some work… for _, rmdir := range rmdirs { rmdir() // clean up }
var w io.Writer w = os.Stdout f := w.(*os.File) // success: f == os.Stdout c := w.(*bytes.Buffer) // panic: interface holds *os.File, not *bytes.Buffer
var w io.Writer w = os.Stdout rw := w.(io.ReadWriter) // success: *os.File has both Read and Write w.Write([]byte("w write ")) // w.Read([]byte("w read")) //w.Read undefined (type io.Writer has no field or method Read) rw.Read([]byte("rw read")) rw.Write([]byte("rw write"))
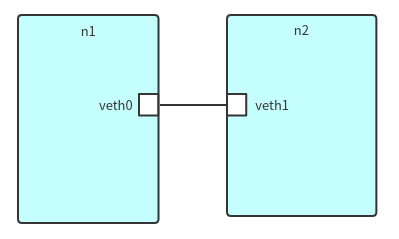
)